
Trust > Generation
32 skills, 5 agents, and the reality of the autonomous software factory. Because scaling generation without verification just scales entropy.


Over the last six months I have been building real software. It started small—a few IT agents, a prototype of a coding fleet manager, a prototype of a micro-SaaS. But as my confidence in the approach grew, so did the ambition. The current project is an Agentic Operating System, a Platform as a Service — not a prototype. A real system.
Like everyone, I started with vibe-coding. And like everyone, I got the dopamine hit of watching code appear fast. What I couldn’t understand was why people were so excited about something that got you to a decent 0.1 and then became Russian roulette for every feature after. Ship something. Break two things. Fix one. Break three more.
I concluded quickly: this is a no-go.
Maybe it’s my background, GlassFish/JavaEE security engineering, Enterprise Jenkins, co-founding Launchable to make Testing smarter. My entire career has been about making software delivery predictable.
In todays world, I started calling it “Fleet Agent Management.” Then Karpathy coined “Agentic Engineering” and I remember thinking: that’s exactly what this is. Not faster agents. Engineering discipline for agents.
I mapped myself on Steve Yegge’s 8 Levels of AI-Assisted Development:

I blew past the early levels quickly. Cursor (Jan-Feb26) felt like a no-go almost immediately. I spent more time undoing what it did than building, except now I had a shiny editor to do it in.
Level 5 felt like home.
Then Beads and Jeffrey Emmanuel’s Agentic Flywheel System—both before Claude Agent Teams existed—pushed me to Level 6, then Level 7. But the results got flaky. I was trying to build my own orchestrator before I’d fixed the underlying trust problem. I was at Level 8 too early.
But here’s what Emmanuel and Yegge didn’t fully capture for me. They talked about managing coding agents. My actual experience was different:
Claude is a super confident teenager who is drunk, has ADHD, and Alzheimer’s at the same time.
My harness tries to keep it in a sane lane.
The problem wasn’t scale. It was trust.
I had spent years in SDLC where TDD, CI, and code review made software delivery genuinely predictable. That predictability was built on trust—trust that a test passing meant something, that a PR review caught real issues, that a deployment wouldn’t silently corrupt state. I had taken that completely for granted. With agents, it was gone.
Trust > Generation.
That’s the equation. Generation improves automatically. Trust has to be engineered.
So I stepped back, fixed the trust problem systematically, and scaled back up. This is the story of how and what I built along the way.
The Harpreet’s Agent Engineering Flywheel (tip of the hat to Jeff Emmanuel for his flywheel) is open source and designed to be picked up one skill at a time.
./install.sh
32 skills, 5 agents, 10 seconds.
Done Was Fake
The first scar was simple: agents said things were done when they absolutely were not done.
But before that, I had a more fundamental problem. I needed to give this ADHD/Alzheimer teenager every possible piece of context before it touched a single line of code. Self-contained tickets, granular enough to be unambiguous, dependency-managed so it knew how to sequence through the epic without asking. In the agent world, Steve Yegge built exactly this: Beads—ticketing for coding agents. (I wrote about this earlier: Beads — Memory and Execution Smarts for Agent-Native Coding.)
Explicit tickets helped. But they didn’t solve the real problem.
Agents would take the ticket, do something, and mark it done. The ticket said “displays user data.” The agent returned a hardcoded string.
Technically: done. Actually: lying confidently.
I added checklists. Review passes. The failures kept leaking through.
Eventually I realized this wasn’t an honesty problem. It was a verifiability problem. I hadn’t been writing code actively for years—Claude brought me back to development. And the first thing this new world dragged me back to was something from a previous life: TDD. The test is the real acceptance criterion. A separate agent writes tests first, dependency-blocked, before any implementation begins. The agent implementing the feature does not define success. A different one, with no stake in completion, does.
The agent that built it doesn’t grade its own work.
Did I say Claude is a teenager cutting homework? It will stub a positive test by returning True and call it done. So the harness runs a mechanical scan — grepping for assert True, trivially passing assertions, hardcoded return values, empty implementations. Fails QA automatically.
Here’s what that whole journey taught me: the disciplines that made software predictable in the first place—explicit scope, verifiable criteria, separation of implementation from review didn’t become irrelevant with agents. They became essential again. The old world had the answers. I just had to remember to bring them.
Parallel Chaos
The next mistake was classic: I fixed individual agent quality and immediately tried to scale.
I built a fleet. Multiple agents, parallel execution, clearing a backlog together. My equation for those early parallel sprints:
4 days to generate the backlog. ½ day to implement it. 3 days to clean up the mess.
The first time this happened I was actually proud — I had delivered what a team would have taken two sprints to ship. The second time I was frustrated. By the fourth time I knew it wasn’t a Claude problem. It was a structural problem I had built.
Two agents editing the same file simultaneously. Shared interfaces drifting apart because nobody agreed on the shape upfront. One ticket silently invalidating the work of another.
I wasn’t shipping faster — I was generating entropy faster.
The fix came in two parts.
Declared file sets: every ticket explicitly claims which files it owns before the sprint starts. Two tickets claiming the same file is a structural conflict. Fix it at planning time, not at 2am debugging why two agents destroyed each other’s work.
Interface contracts: producer and consumer tickets carry identical Contract blocks—byte-identical, agreed upfront. Parallel agents cannot “kind of agree” on a shared type. Either the contracts match or the sprint doesn’t start.
A lesson from 2000. Still applies.
Today my sprints run in 1.5 days ¾ day shaping and planning, ¼ day implementation, ½ day debugging.
Yegge calls this shortened development model—the campfire model: no waterfall, everyone sitting around a living prototype, building together. That’s exactly what it feels like. The harness is what makes the campfire possible without burning the house down.

The Alzheimer’s Problem
Every session, Claude would set up the Supabase preview branch. Every session, same broken recipe. Same wrong seed data. Same missing bootstrap step. Same confident “environment is ready”—right before the tests blew up.
The first time I put it down to a bad session. The third time I realized what was actually happening. Claude didn’t remember the recipe had failed. It didn’t remember we’d fixed it. It didn’t remember the conversation at all. To Claude, every session is day one.
This is the Alzheimer’s problem. And it’s the most insidious of the three because it’s invisible. Bad code is visible. File collisions are visible. Context loss looks exactly like a fresh start which is exactly what Claude thinks it is.
I noticed at some point that I was doing something repetitive: re-explaining the same architectural decisions every session. Re-briefing the same environment setup. Re-establishing context that had dissolved overnight.
I had become the memory layer.
I was doing manually what the harness needed to do architecturally.
The fix isn’t better prompting. It’s architecture.
stash and hydrate are wired as pre and post-compaction hooks—automatic, not manual. Before context compacts, the system declares what matters. After, it restores it intentionally.
Inference is not memory. You tell Claude what to remember before it forgets.
That solves session memory. The harder problem is cross-session memory — lessons that need to survive beyond a single conversation.
CM and CASS Jeffrey Emmanuel’s work—solve this across sessions. Every skill queries them before starting: have we solved this before? The answer is already there. No reinvention.
Serena handles codebase navigation via code intelligence rather than text search. Following symbols, not scanning strings.
And for structure, the part that changes slowest but costs the most to re-derive— I pre-commit it at two levels.
Global: the system topology, SHA-anchored, committed to the repo root:
---
scope: joystream
generated_from_sha: d0896b8
last_verified: 2026-06-03
confidence: high
---
flowchart TB
subgraph Clients
FE["frontend/ — Next.js App Router"]
CLI["cli/ — Typer HTTP client"]
end
BE["backend/ — FastAPI / 26 routers"]
subgraph Engines
DAG["JoyStream DAG executor"]
OC["OpenClaw runtime"]
end
SB[("Supabase Postgres")]
LLM["LLM providers (Anthropic)"]
FE --> BE
CLI --> BE
BE --> DAG & OC & SB & LLM
Local: every feature gets its own architecture diagram, committed into the feature context before the sprint starts. Not just how the system works—how this feature fits and how it flows:
---
scope: multi-login
generated_from_sha: d0896b8
last_verified: 2026-06-03
confidence: high
---
flowchart TB
L["user logs in"] --> C{username null?}
C -- yes --> G["UsernameGate blocks app"]
G --> P["UsernamePicker: availability check"]
P --> RPC["set_username RPC"]
RPC --> A["atomic: users.username + shared_handles"]
A --> R["gate unblocks"]
C -- no --> R
Same format. Two layers. Every agent reads both before touching a file. Global orientation. Local flow. Not 50 source files but these two documents.
I used to write “here’s how the system fits together” docs for new engineers on their first day. I stopped doing it for Claude. That was the mistake.
Pre-committed knowledge is nearly free. Re-derivation is expensive. Context pre-loading isn’t a prompt trick. It’s an engineering decision.
You Stop Being in the Room
At some point I realized I was answering questions for the entire sprint.
“Should I refactor this?” “Which dependency?” “This conflicts with ticket 12.” “Should this be abstracted?” Every decision routed back to me. I had a fleet of agents and I was still the bottleneck.
The Director changed that.
The Director (Opus) manages the sprint. Workers escalate to the Director, not to me. Wave structure, gates, dependency management, collision-free assignment — the Director owns all of it. I supervise the Director. That’s the intended shape of my involvement mid-sprint.
This is what a real sprint looks like:

19 beads. 6 waves. 2 workers. The dependency chain is 6 levels deep—that’s the bottleneck, not worker count.
And at the top of every sprint plan, one line that matters more than any other:
Trailing escape rate 23.1% (≥20%) → do NOT increase worker count.
That’s the gate. Below 20% rework, you scale. Above it, more agents just amplify the problem faster.
I’ll be honest about where this stands: the escape rate gate is newly wired. In practice today, I review the plan before launching—if I see more than five or six agents for twenty-odd beads, I pare it down. Rate limits are real when you’re working solo. In a real engineering team, escape rate is the natural governor — rework costs human time and you feel it. With agents, it’s tokens and API calls and you don’t feel it until the bill arrives. The metric brings that signal back. The measurement is right. The tuning is ongoing.
The organizational shift, though, is not ongoing. It happened the day I added the Director.
You stop being in the room. Workers route to the Director. The Director routes to you only when it’s genuinely stuck. A sprint that ran well is one where I barely noticed it was happening.
AI Made SDLC Mandatory
Somewhere towards the end of the first quarter, I noticed something uncomfortable.
Everything I was building looked familiar.
Interface contracts—agreed types between producer and consumer, enforced upfront. Compile-time conflict detection. Dependency graphs. Test-before-implement. Review separation—the builder doesn’t grade their own work. Wave gates before advancing. CI parity.
These weren’t new ideas. These were the exact disciplines the industry had spent forty years building. I had worked at their intersection my whole career: CI for enterprises with Enterprise Jenkins, AI for smarter tests at Launchable. I had taken them completely for granted. With agents, they weren’t optional anymore.
The ci-preflight scar is an honest one. Agents would pass local tests, push, and immediately break GitHub Actions on a lint error. Repeatedly. ci-preflight now runs the exact sequence GitHub Actions will run, in the same order, before any commit is pushed. We built CI twenty-odd years ago to catch exactly this class of problem. I just had to remember to apply it before the push, not after.
fresh-eyes is the other one. An agent working a feature accumulates familiarity—it knows why choices were made, it’s seen the code evolve, it has context that’s now a liability for review. fresh-eyes drops everything and reads cold, like an engineer seeing the codebase for the first time. The best reviewer wasn’t in the room. That principle is older than I am.
The productivity gain is real. I won’t walk it back. But the entropy gain is equally real, and nobody talks about it. Agents generate broken state faster than humans do. They produce plausible-looking output that fails downstream. They make confident claims that don’t survive CI. They move fast and leave messes.
Human engineers learn—slowly, over careers to be conservative. To leave notes. To check before pushing. To ask before refactoring. Agents don’t have that learned caution. They have capability without the scar tissue.
SDLC discipline was the scar tissue. We built it to manage human entropy. Agents have more entropy, not less. The disciplines don’t become overhead— they become the floor.
Level 8
Steve Yegge’s 8 Levels of AI-Assisted Development is the clearest map I’ve found for where people actually are versus where they think they are. I want to add a row.
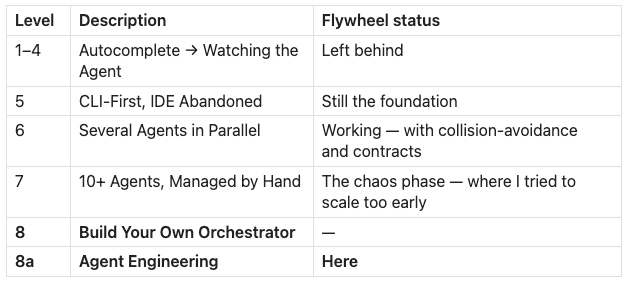
I planned to build a software factory. I didn’t plan to need all of this to get there. The scars kept forcing me deeper.
But Level 8 covers two distinct things. Building the orchestrator—new runtimes, new tooling, new composability layers—is what GasTown, Agent-Flywheel.com, and Claude Agent Teams are doing. Well-capitalized, moving fast. Not a battle worth taking on. The orchestrators will keep getting better regardless.
Agent Engineering is the other thing: the discipline that makes any orchestrator reliable. That’s Level 8a. That’s what I’ve been doing.
Orchestrators manage agents. Agent Engineering manages trust.
My skills work with Claude Agent Teams because that’s where I focused when I realized they’d pulled in a number of concepts from Agent-Flywheel. But that wasn’t enough. I had to pull in CM and CASS from Agent-Flywheel, then Serena. Agent-mail is next. The harness accretes. Each addition closed a gap the previous layer left open.
GasCity, the engine underneath GasTown is genuinely promising. Looking at what they’ve built, many of the same concepts are already there. Taking the flywheel skills to work with GasTown is an experiment I’m planning this quarter. The vision is an engine where teams throw their beads at it and get working software back. Solid beads, disciplined harness, capable orchestrator underneath. That world is what I’m building toward.
There’s also a philosophical difference from Yegge and Emmanuel worth naming. Their model is fundamentally ephemeral: throw work at agents, trust the system to execute. It works because they’ve earned that trust.
My instinct was different: map how human engineering teams build trust through process and apply that structure to agents. Director as tech lead. QA agent as QA engineer. Workers in defined lanes. Waves as sprints. Gates as code review.
Neither is objectively better. They trust their system more readily than I trust mine and I’m working on closing that gap. My path to trust runs through structure.
That’s Agentic Engineering. Not building an orchestrator building the engineering around one.
Honest ceiling:
8 out of 10. The gap is visual UI verification. Agents cannot see what they render. A stub that returns a blank <div> with the right class name passes every mechanical check—tests, types, CI, all green. The UI is empty. I’m still the final arbiter of visual polish, and until agents can see a viewport, that won’t change.
The threshold for scaling is a trailing escape rate below 20%. I’m measuring now. The measurement is the next unlock. The point is that this is a living system not a static one.
The On-Ramp
The repo is open source. ./install.sh—32 skills, 5 agents, configured in under ten seconds.
Think of it in two layers.
The runtime layer: Claude Agent Teams, GasTown/GasCity, Agent-Flywheel. These are the engines — they manage how agents run, communicate, and get work assigned. All capable. All moving fast.
The Agent Engineering layer: the harness that makes any runtime reliable. TDD pairs. Declared file sets. Memory architecture. Wave gates. Escape rate measurement. This is what the flywheel skills provide. Designed to work on top of whichever runtime you choose.
Together: the software factory I set out to build from day one—something that would take one person and multiply their output. The scars weren’t detours. They were the build process.
Some honest context on the runtimes:
I spent a month building with Agent-Flywheel. It’s the originator—deep on the orchestration side, and everything here is a direct extension of Emmanuel’s work. If you want to understand where these patterns come from, start there.
I played with GasTown in March. In AI time that’s ancient history—I’d be doing them a disservice to compare today’s version to what I saw then. What I do know is that GasCity, the engine underneath it, has converged on many of the same architectural ideas. Taking the flywheel skills to GasTown is an experiment I’m planning this quarter.
Claude Agent Teams is where the skills run today—that’s where I focused once I realized they’d internalized enough of the right patterns to be the current foundation.
You don’t have to adopt the whole thing at once. Start with the scar you’re feeling right now. stash and hydrate for session memory. beads-create for TDD pairs. ci-preflight for CI surprises. The system accretes. You accrete with it.
github.com/harpreetsingh/harpreet-agent-flywheel-skills — 32 skills, 5 agents, 10 seconds.
I set out to build a software factory. The goal from day one was to take one person and multiply their output—not incrementally, but by an order of magnitude. Something that would feel like running a real engineering team.
What I didn’t plan for was that scale was the easy part. Trust was the hard part. You can’t multiply output you can’t verify. You can’t scale agents that aren’t reliable. Every skill in this repo is the answer to a specific trust failure I hit on the way there.
The flywheel runs a real sprint in a day and a half. That’s not a tweet. It’s the measured result of everything documented above: ¾ day shaping and planning, ¼ day implementation, ½ day closing. The factory is real.
Right now I’m using it to build something bigger—an agentic operating system, a platform where the factory (a different factory than what this blog describes) itself becomes the product. But that’s a different post.
Trust > Generation. Generation improves automatically, on a curve that bends upward every month without your help. Trust doesn’t. Trust has to be engineered. Build the trust layer, and the factory follows.